Feb 27, 2025
When “almost right” is catastrophically wrong: Evals for AI learning games

Imagine you’re solving a momentum puzzle in our Scientific Thinking course.
You line up the shot, position the cue ball at the perfect angle, and... the eight ball stops just short of the pocket. You adjust and try again. Same result. Third attempt—your physics intuition is sound, your reasoning correct—yet the ball still refuses to drop.
The problem isn’t your understanding. It’s that the puzzle itself is broken.
This may be difficult to watch.
This seemingly minor flaw – a ball that stops just short of its target despite correct player inputs – isn’t just frustrating. In a learning environment, it’s catastrophic. You might question your understanding of momentum, doubt your calculation skills, or worse, develop an incorrect mental model that you carry forward.
For learning games, “almost right” is completely wrong.
The 100% correctness challenge
In our previous post, we talked about using AI to help us generate interactive learning puzzles at scale. But we glossed over the most critical challenge: ensuring that every single one of those puzzles is not just functional, but flawlessly correct.
When you’re building thousands of puzzles across dozens of STEM concepts, even a small percentage of errors means multiple broken puzzles in every course – each one a potential stumbling block for learners. Yet manually checking every scenario in every puzzle would make it impossible to scale.
This is where our evals framework comes in.
Beyond “Does it compile?”
Most software testing asks a simple question: “Does it run without errors?” For many applications, that’s challenging enough. At Brilliant, we’ve already set a high bar with our tech stack choices – using tools that help eliminate entire categories of runtime errors through robust type systems. If our code compiles, it’s unlikely to crash.
But for learning games, even that reliability is just the beginning. Our puzzles need to meet a much higher standard:
Our evals test puzzles across multiple dimensions:
- Mathematical correctness: Do equation-building puzzles follow algebraic rules? Are mathematical operations valid within the problem context?
- Unique solvability: Is there exactly one solution given the degrees of freedom? This is sometimes critical, and sometimes avoided for more open-ended challenges.
- Visual clarity: Are all puzzle elements properly positioned without overlapping? Can users clearly distinguish between different components?
- State consistency: As users interact with the puzzle, does it maintain logical behavior throughout all possible states?
- Impossible states: Can the user manipulate the puzzle into a state that breaks the simulation or creates mathematically undefined conditions?
- Physical plausibility: Does the puzzle respect the laws of physics? Does a structural system properly distribute forces? Do light rays reflect at the correct angles?
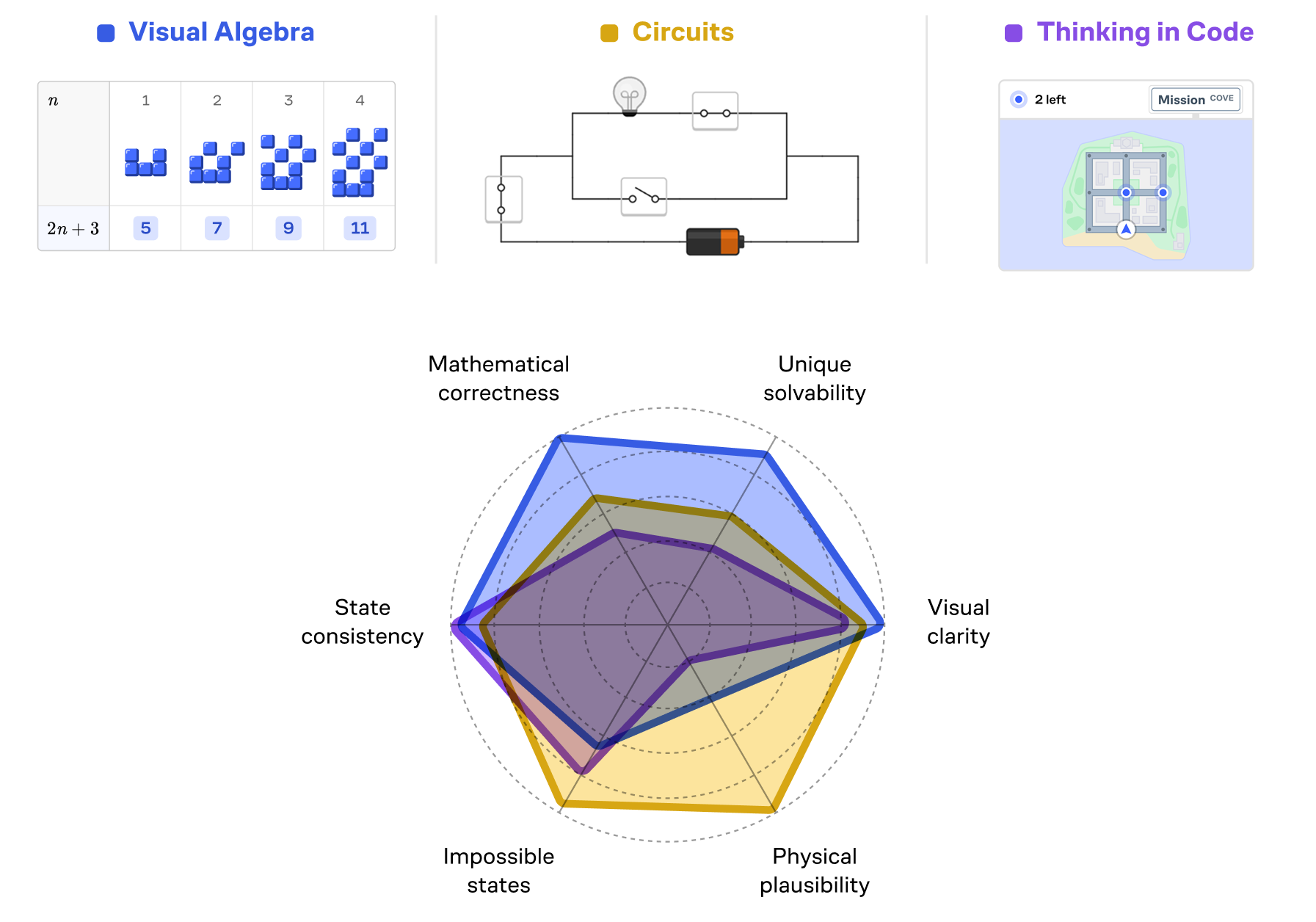
Getting all of these right simultaneously is exceptionally hard – especially when you’re asking an AI to help generate puzzles at scale.
Case study: The evolution of mobile puzzles
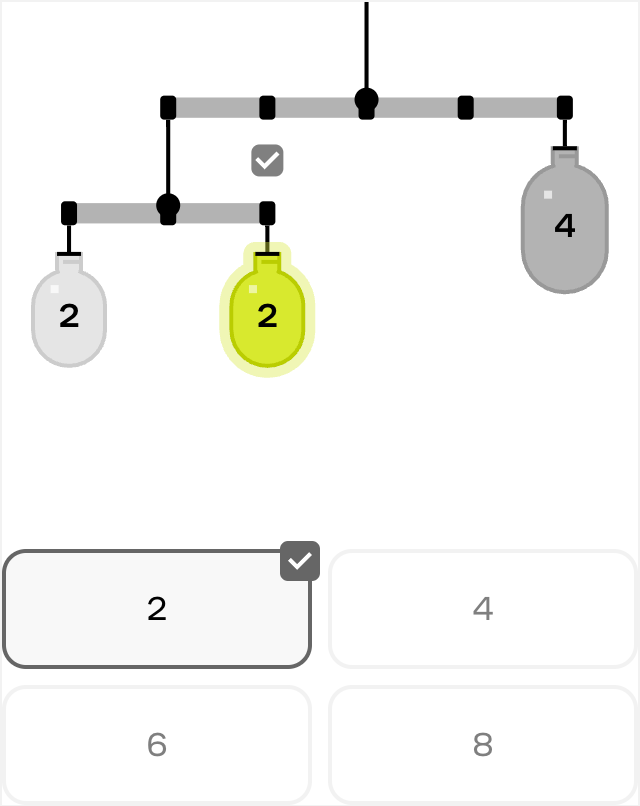
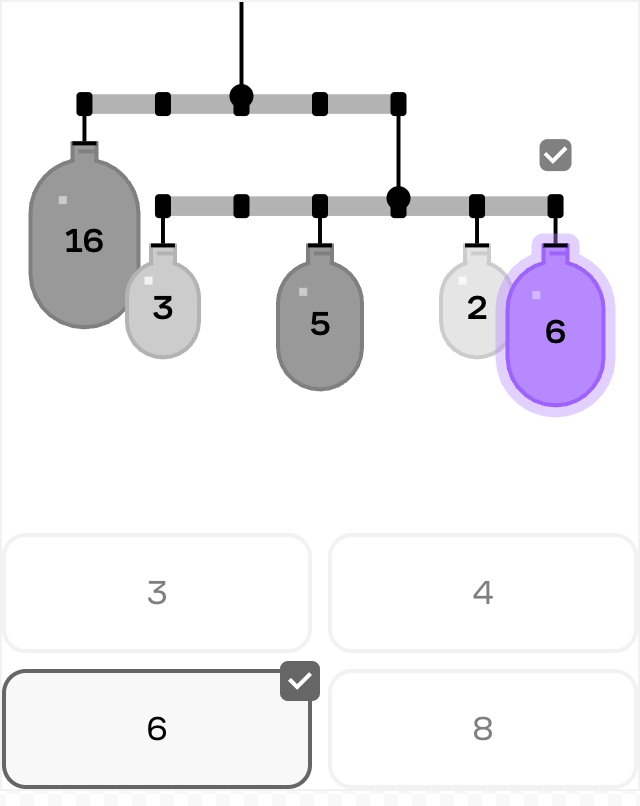
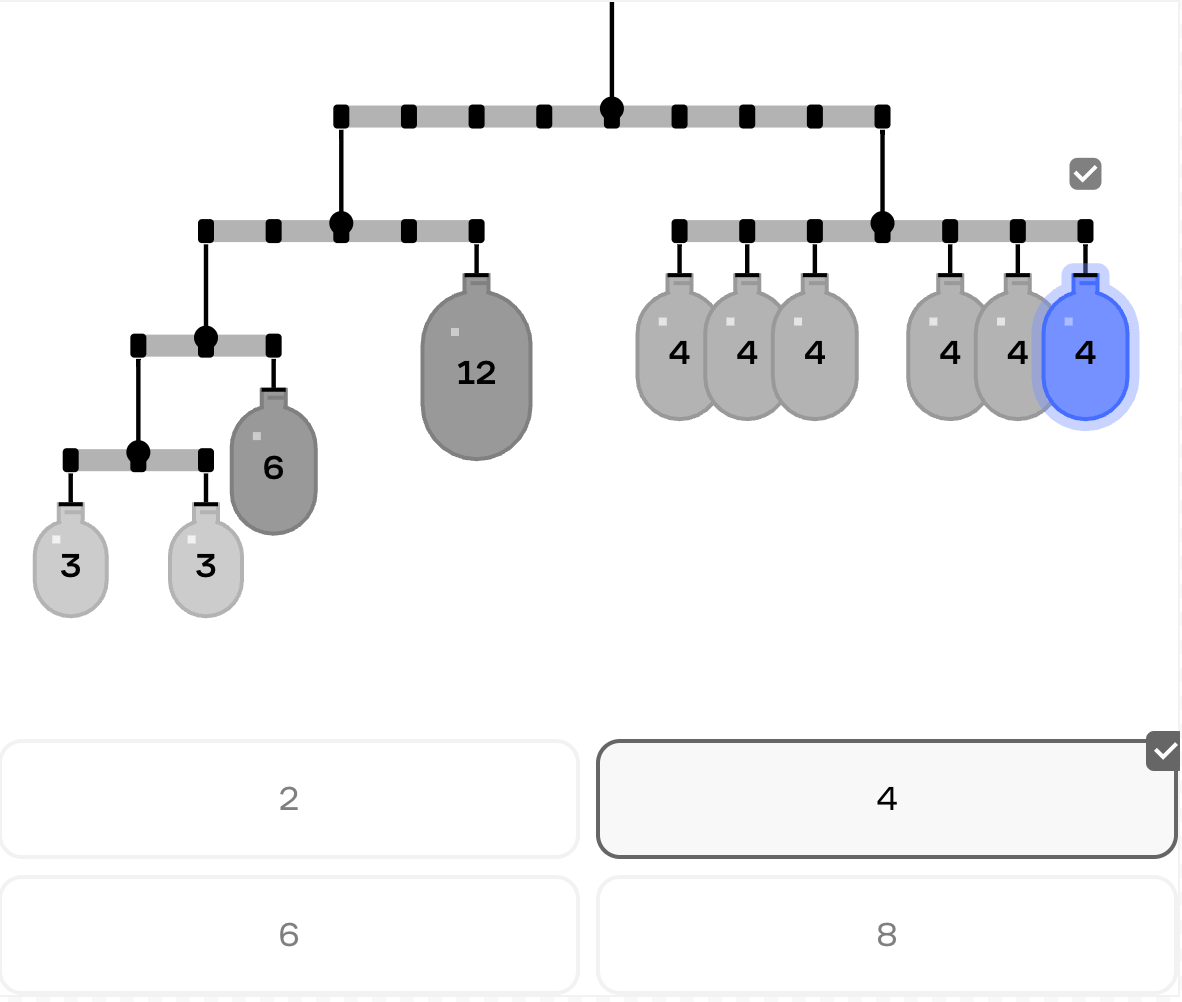
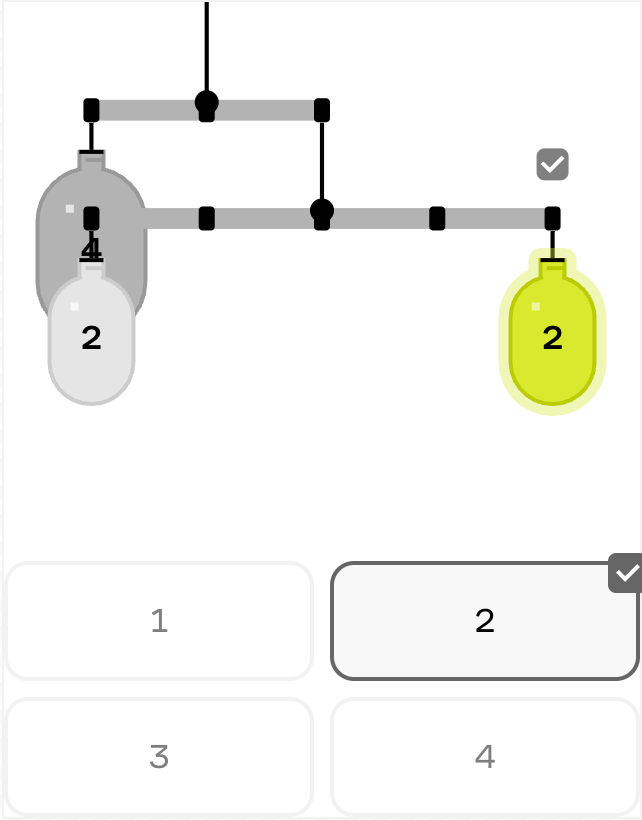
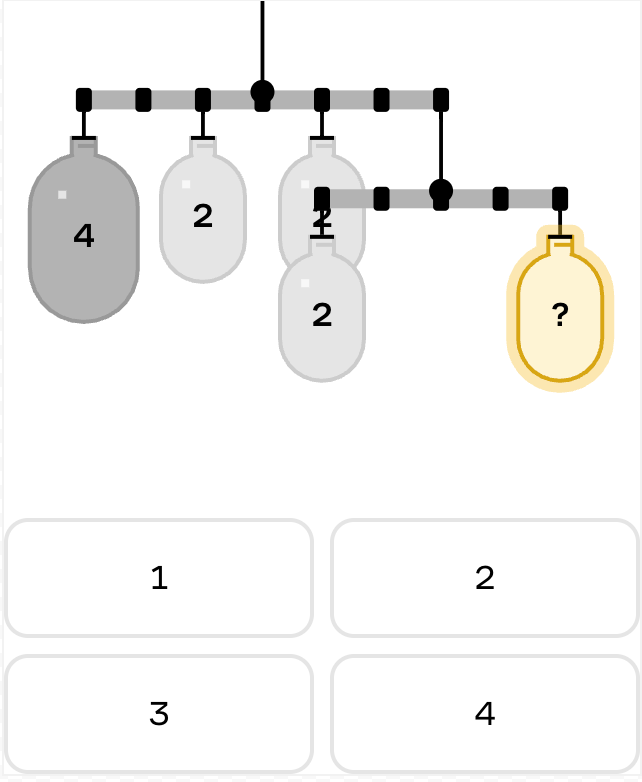
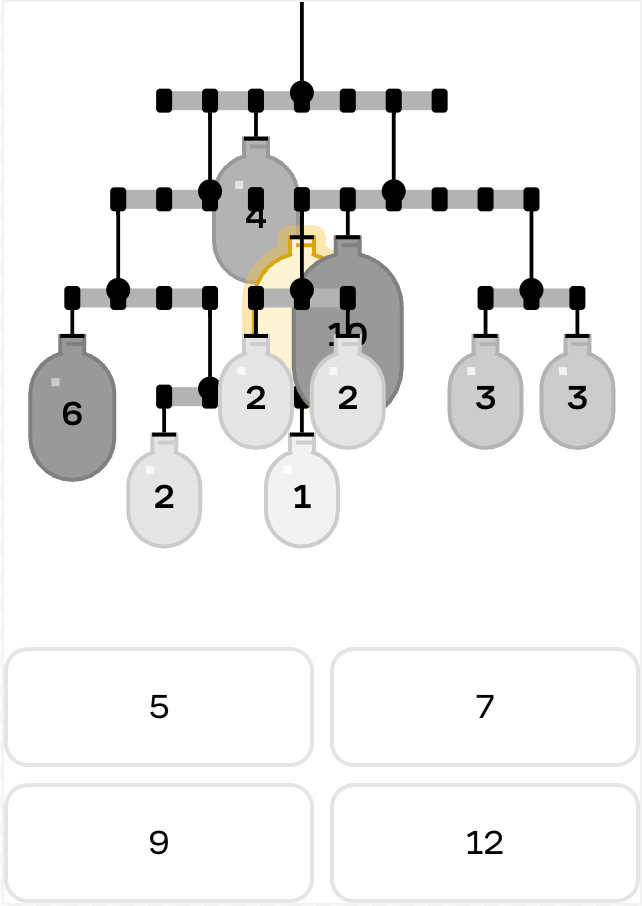
To show how our evals framework has evolved, let’s look at our mobile equilibrium puzzles, where learners balance objects of different weights on a system of rods and pivot points.
Our first LLM-generated mobile puzzles were structurally sound but had serious playability issues. This is a common challenge when puzzles require both spatial awareness and mathematical correctness – mobiles demand a precise intersection of physical arrangement and algebraic balance.
Many weren’t solvable with our integer-spaced placement system (a simplifying constraint we use to make puzzles more approachable). Others couldn’t be solved using only the drag-and-snap points that were made available to users. Some suffered from visual clarity issues, with weights and rods overlapping each other in ways that made the puzzle difficult to understand and manipulate.
| Foundational | Advanced | Extreme | |
|---|---|---|---|
| Pass |
|
|
|
| Fail |
|
|
|
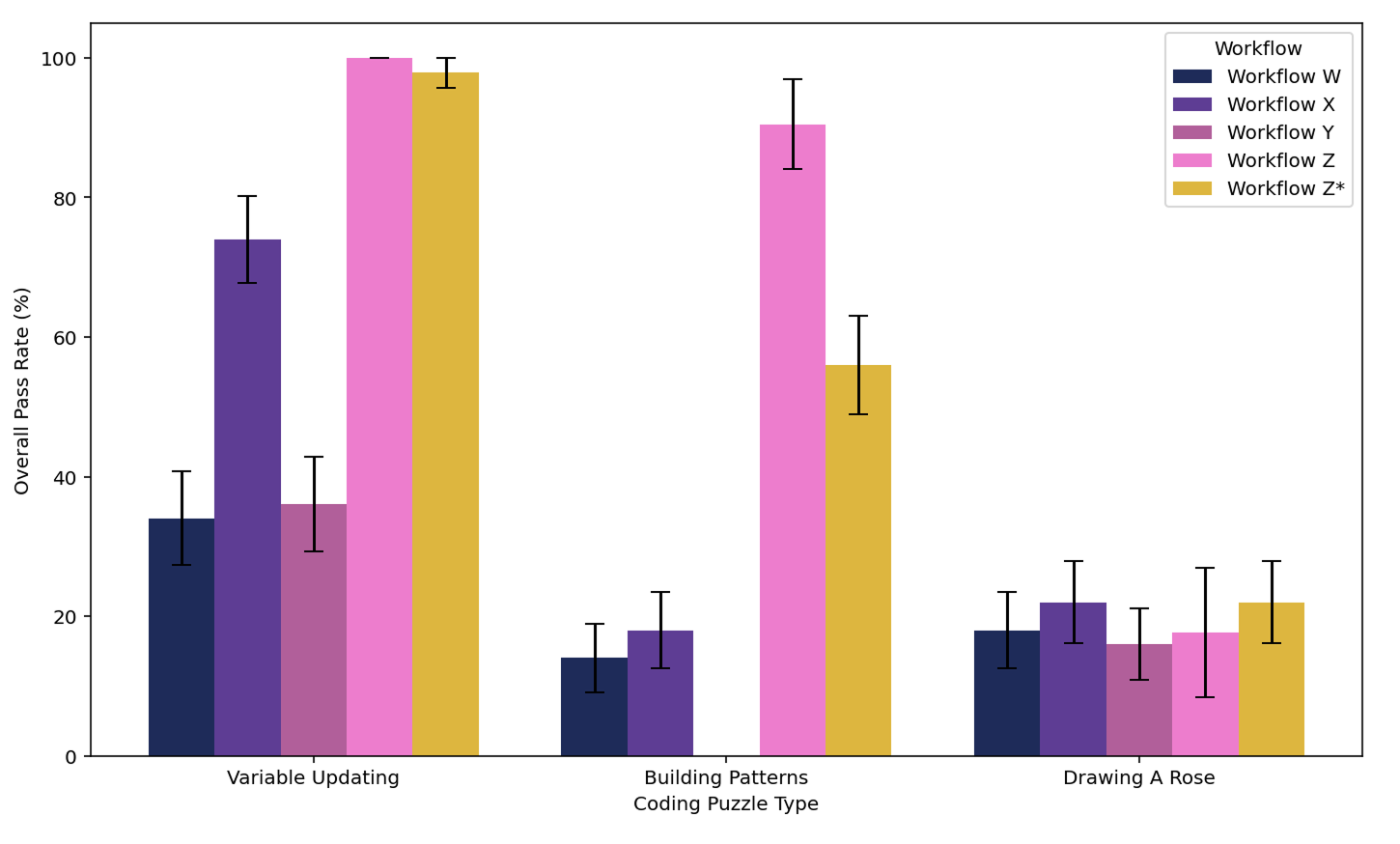
We measured our success rate across several key metrics:
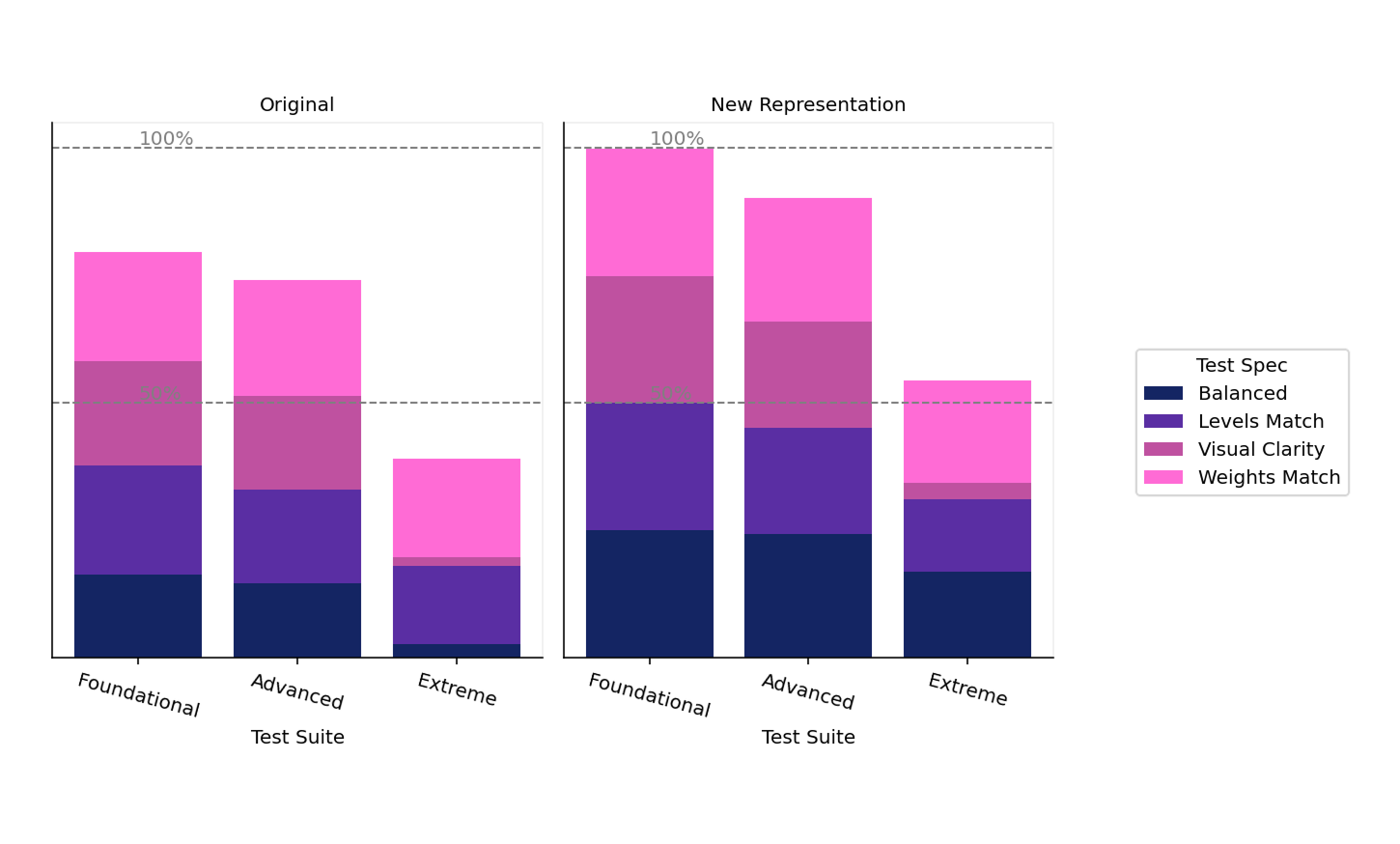
Our initial attempts produced puzzles with high structural validity (they compiled correctly) but couldn’t be balanced. With time and effort, we improved somewhat, but still faced challenges with visual clarity in rendering and solvability.
Then came a breakthrough – changing the puzzle representation the LLM was generating dramatically improved metrics – and our evals framework enabled us to evaluate metrics that were previously impossible to quantify.
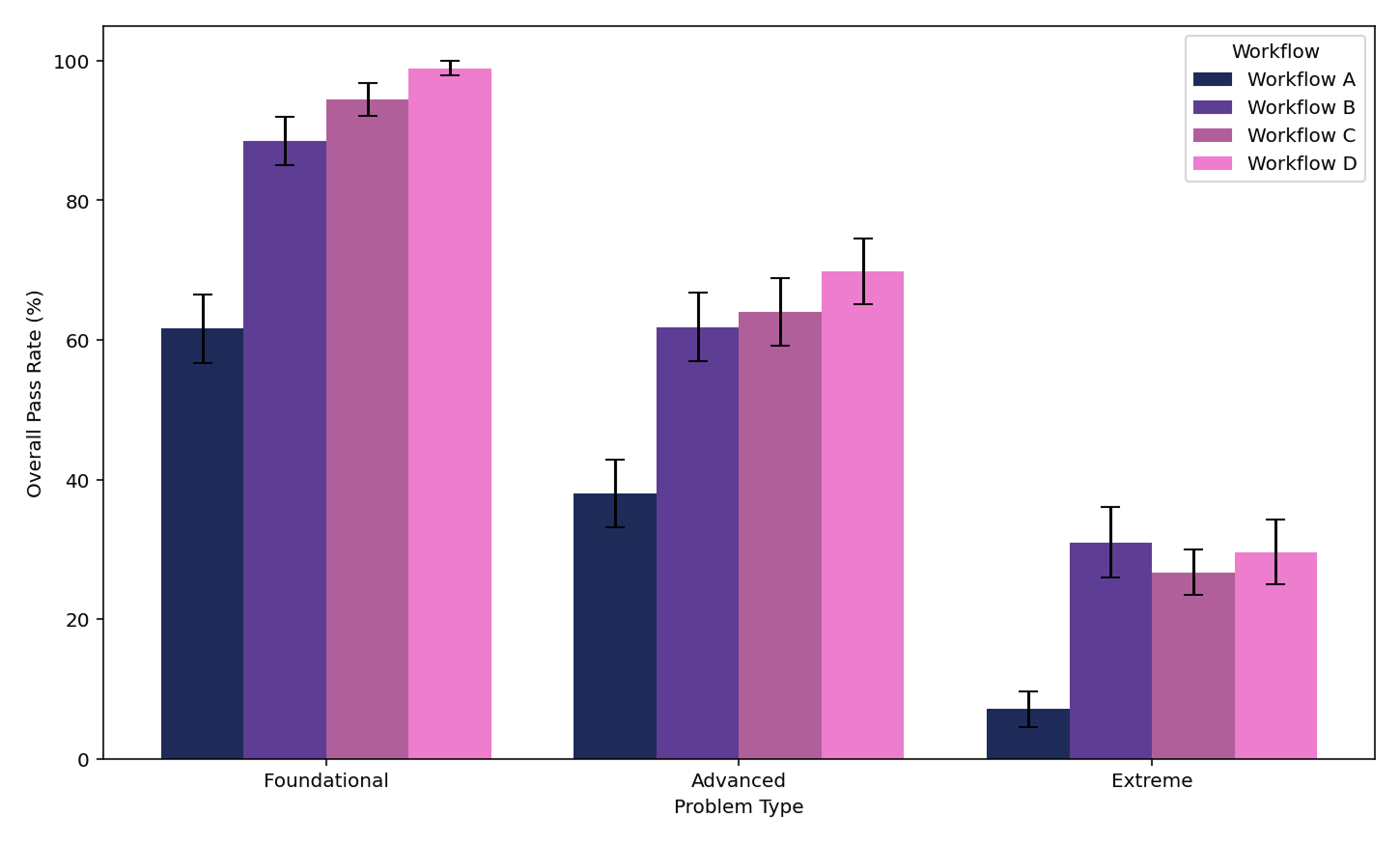
Today, our success rate sits in the 80-90% range across all dimensions for foundational problems – and the puzzles that fail the evals never even make it to the human review process. This represents a dramatic improvement in efficiency while maintaining our quality bar.
The more challenging balance problems with many layers, draggable weights, and unknowns remain difficult even for frontier models (but are also too difficult for most of our users!)
Scaling evals across game types
The real power of our approach is how it scales across different game types. Each game type presents unique evaluation and generation challenges:
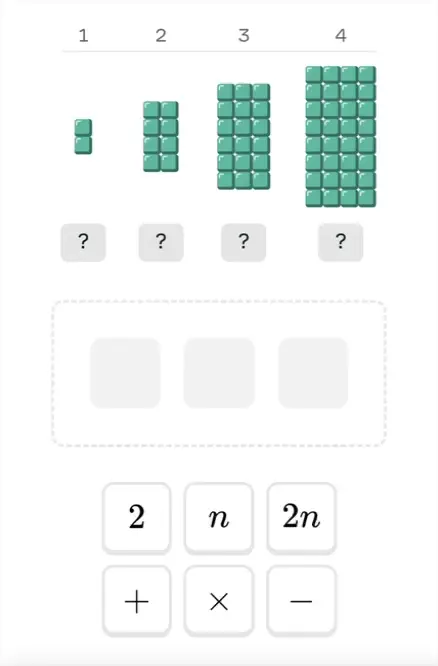
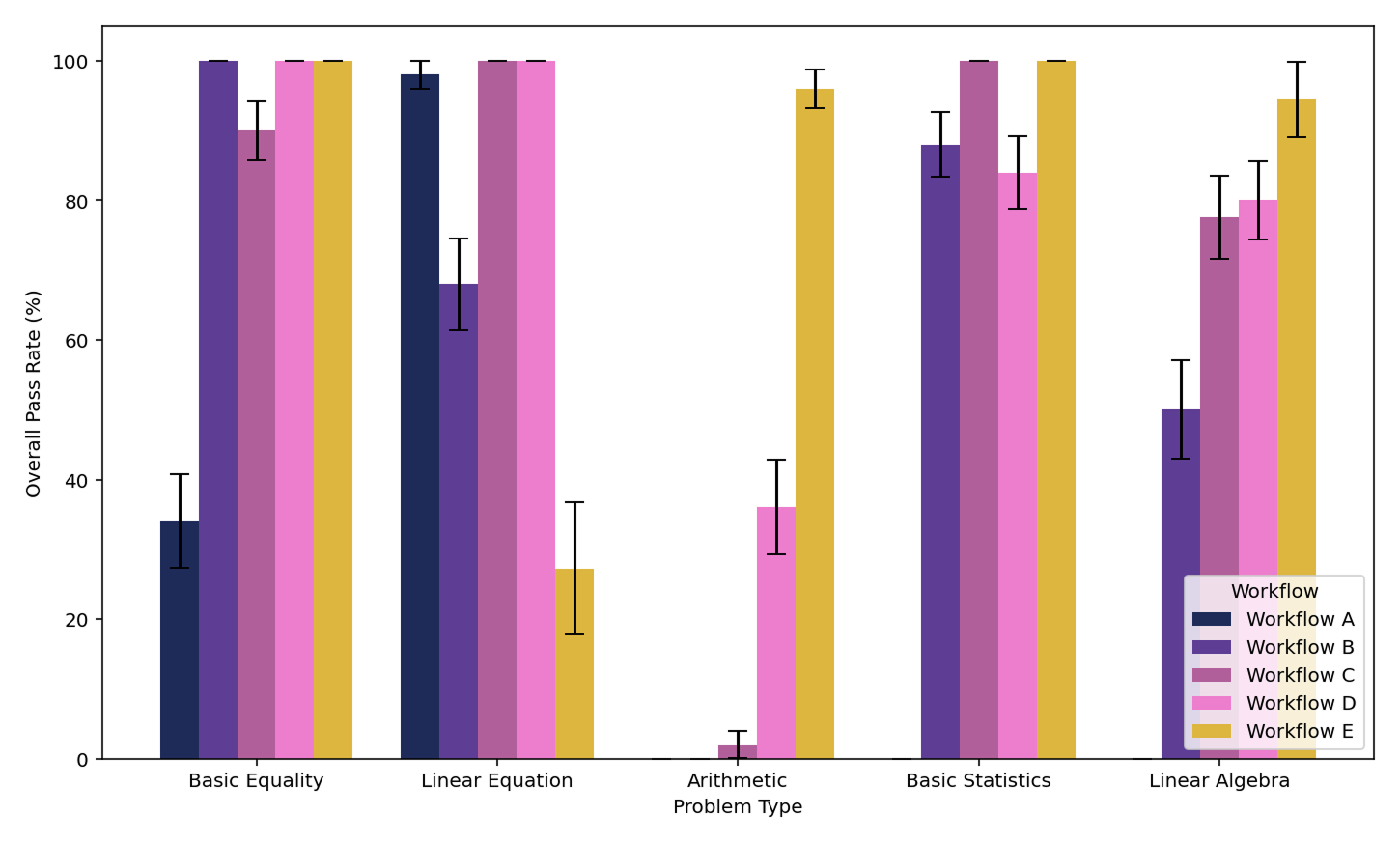
Mathematical equation puzzles
For drag-and-drop arithmetic and algebra puzzles, our evals framework verifies that valid equations can be formed with the available tiles and that the resulting expressions are mathematically sound within the given constraints. We can benchmark the tools our workflows have used, and we’ve had gains in arithmetic, algebra, and vector puzzles.
Logic puzzles
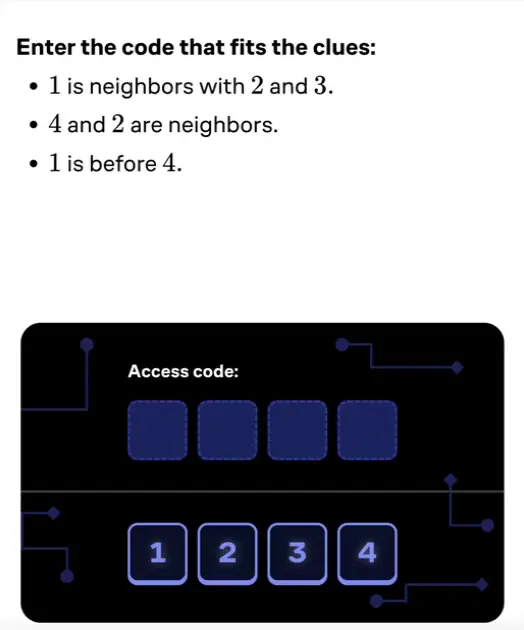
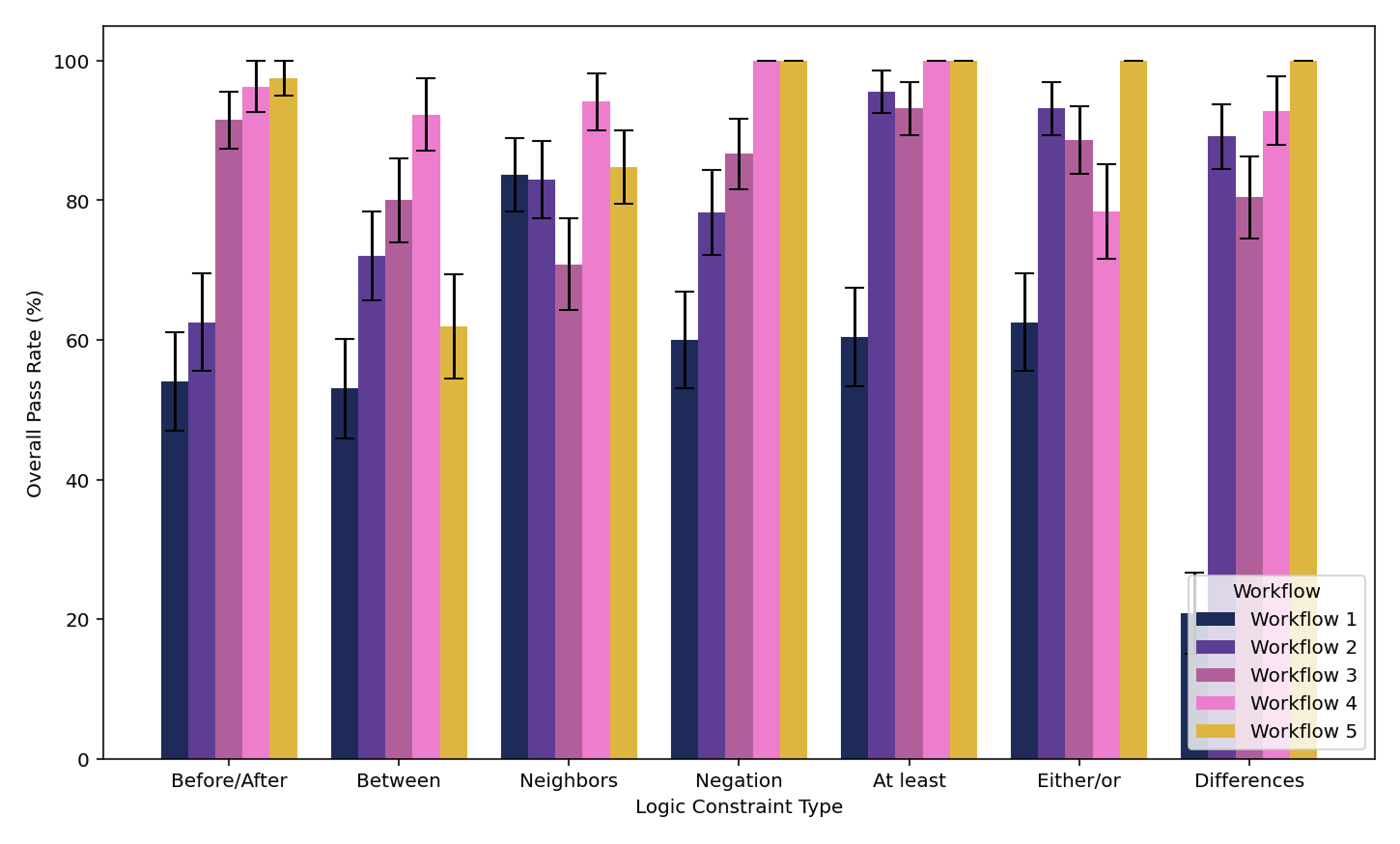
With order logic puzzles, our evals ensure all clues remain logically consistent (e.g., “3 is neighbors with 4 but not 1” or “the number of 3s equals the digit in position 1”). The challenge lies in verifying that every puzzle has exactly one solution while testing against diverse constraint types. There’s nothing more frustrating than spending 10 minutes on a logic puzzle only to discover it's unsolvable – a mistake we’ve gotten better and better at avoiding.
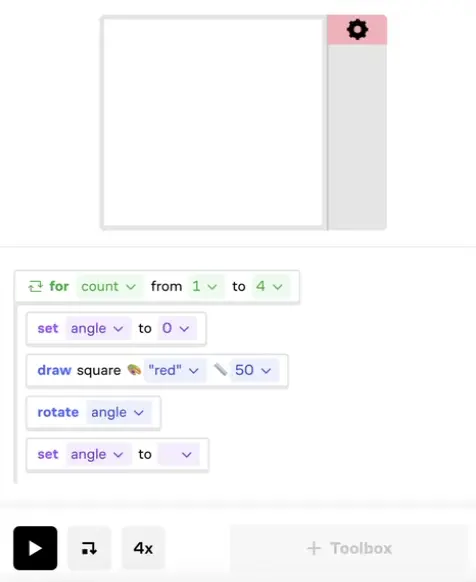
Drag-and-drop coding puzzles
The evals framework must verify that goals are achievable with the provided code blocks. For drawing puzzles, this means ensuring blocks contain the necessary parameters (like controls for creating, sizing, and transforming shapes).
Our evals framework rapidly evaluates generated puzzles against our quality standards, automatically filtering out problematic ones. This frees our learning designers to focus on refining the best candidates rather than manually checking every puzzle for correctness!
This tight feedback loop between designer intention and evaluation metrics has transformed our workflow. What once took weeks of careful handcrafting and testing now happens in hours, with higher quality results.
The hardest evals yet
Some of our newly launched and in-development courses involve especially challenging evaluation problems:
- Optical and circuits puzzles where possible paths and interactions are difficult to predict without simulation
- Everyday math puzzles that require balancing arithmetic operations, statistical reasoning, and probability calculations
- Recursive and iterative puzzles where small initial changes compound dramatically through multiple calculation steps
These represent the frontier of our evals framework – problems where the layout is key, and where seemingly small changes can have outsized effects on solvability.
Building the future of learning games
We’re making progress every day, but these games still require significant human expertise to evaluate properly. The collaboration between our AI tools and our human experts remains essential to maintaining our quality standards.
At Brilliant, we’re obsessed with creating learning experiences that click through doing, not reading. Our evals framework has transformed how we create puzzles, allowing us to scale while maintaining the quality our learners expect. Getting these puzzles right – truly, mathematically, physically right – isn’t just a fun technical challenge. It’s core to our mission.
If you’re excited about the intersection of AI, game design, and learning science, check out our open positions. Help us build the future of interactive STEM education, one perfectly evaluated puzzle at a time.